Monitoring and Alerting on your Kubernetes Cluster with Prometheus and Grafana

Why Are Monitoring and Alerting Important?
IT Teams already realize the necessity of monitoring their infrastructure. There is a long history and many products available for legacy infrastructure: tools like Nagios, Zabbix, and others are familiar players in this space.
But, with the Kubernetes ecosystem, it brings many levels of abstraction and troubleshooting if you don’t have the right tools. How many DevOps engineers are faced with the familiar error:
Failed scheduling No nodes are available that match all of the following predicates::Insufficient CPU
Cluster resource monitoring is essential to follow in real time. In comparison with traditional infrastructure, cluster resources are constantly scaling and changing. You can never know where your pods will be launched on your cluster. For these reasons, we need to monitor both the underlying resources of the cluster and the inner cluster health.
On top of that, monitoring alone is not enough if you’re not utilizing alerts. We can easily imagine that our OPS will not stay all night looking at their dashboards on critical production clusters.
Why Prometheus and Grafana?
With an extensive set of alerting and monitoring tools, why should we go for Prometheus and Grafana specifically?
Prometheus
Prometheus is an open source monitoring tool. It was initially developed at Soundcloud but is now a standalone open source project, part of the Cloud Native Computing Foundation (CNCF) in 2016. It is the second project after… Kubernetes itself. This is the first reason why both components are often associated as tightly coupled projects.
In addition to that, Prometheus differs from numerous other monitoring tools as its architecture is pull-based. It continuously scrapes metrics from the monitored components.
Finally, in the architecture itself, Prometheus uses a multi-dimensional data model very similar to the way Kubernetes organizes its data by labels. In opposition to a dotted data model where each metric is unique and each different parameters requires different metrics, with Prometheus, everything is stored as key/value pairs in time series:
<metric name>{<label name>=<label value>, …}Prometheus architecture includes three main components :
- The prometheus server itself : which collect metrics and answer to queries via API
- A pushgateway : to expose metrics for ephemeral and short jobs
- An alertmanager : to enable the alerts publication as name suggests
We will be using here a combination of the prometheus node_exporter and kube_state_metrics to publish metrics about our cluster.
Grafana
Grafana is a popular open source (Apache 2.0 license) visualization layer for Prometheus that supports querying Prometheus’ time-based data out of the box. In fact, the Grafana data source for Prometheus is included since Grafana 2.5.0 (2015–10–28).
It is, on top of that, incredibly easy to use as it offers template functionality allowing you to create dynamic dashboards editable in real-time.
Finally, there is a very good documentation and a vast community sharing, among other things, public dashboards. We will use two public dashboards specifically made for Kubernetes in this article.
After all this theory let’s get our hands dirty!
Prerequisites for Installation
The only requirement we have for this project is a working kubernetes cluster. For the sake of simplicity, I will be using in this article a minikube installation on AWS EC2.
Minikube is a convenient way to install a single-node Kubernetes cluster for non-production, lab, and testing purposes. It is especially effective on individual computers, as it doesn’t come with heavy resource requirements, and it supports several K8s features out-of-the box.
It works normally by creating a local VM on the machine relying on a hypervisor, but being on a AWS VM myself I’ll be using vm-driver=none mode of Minikube for this demonstration.
Install Prometheus and Grafana with Helm
It is time to install both products. We will rely on Helm, a Kubernetes package manager which updated to version 3.0 in November 2019.
Just for history, this update is very important as Helm was deeply rewritten to catch up with Kubernetes evolutions like RBAC and Custom Roles Definitions. It makes it a lot more production-compliant than previous versions. Previously, many IT experts were reluctant to use Helm for production-grade clusters due to its permissive security model and its dependence on the controversial Tiller component (now removed from 3.0).
We will use charts (Helm’s packaging format) from the stable Helm repo to help getting started with monitoring Kubernetes cluster components and system metrics.
Installing Helm
Add the stable repo to your Helm installation:
$ helm repo add stable https://kubernetes-charts.storage.googleapis.com/
$ helm repo updateThen we will create a custom namespace on our K8s cluster to manage all the monitoring stack:
$ kubectl create ns monitoringInstalling Prometheus
We can install now the Prometheus chart in the newly created monitoring namespace
$ helm install prometheus stable/prometheus --namespace monitoring
NAME: prometheus
LAST DEPLOYED: Tue Apr 14 09:22:27 2020
NAMESPACE: monitoring
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
The Prometheus server can be accessed via port 80 on the following DNS name from within your cluster:
prometheus-server.monitoring.svc.cluster.local[...]
Then we can create a NodePort using K8s’ native imperative command which allows us to communicate directly to the pod from outside the cluster. Just know that this step is optional if you don’t intend to query Prometheus without Grafana.
We can see the port 30568 was automatically allocated to map the 9090 port to the pod.
I can now access the Prometheus endpoint using my public DNS and port 30568 in my browser.
There, we can directly query Prometheus to get, for example, CPU consumption by namespaces using the following command:
sum(rate(container_cpu_usage_seconds_total{container_name!=”POD”,namespace!=””}[5m])) by (namespace)
Installing Grafana
Now that Prometheus is installed, rather than querying each metric individually, it is way more convenient to use Grafana to get comprehensive dashboards aggregating multiple metrics in one place.
We use helm once again to install grafana in the monitoring namespace :
$ helm install grafana stable/grafana --namespace monitoring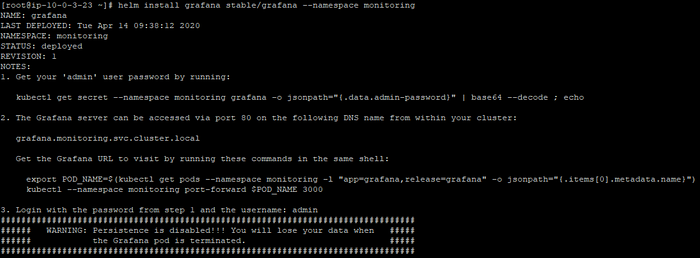
We can see that grafana pod is running along the prometheus components
Here again we create a NodePort service to access Grafana from outside the cluster (this time it is mandatory) :
$ kubectl -n monitoring expose pod grafana-5b74c499c6-kt4bw --type NodePort --name grafana-npservice/grafana-np exposed
And get the external port mapped to Grafana listening port 3000 : (here 31399)
$ kubectl -n monitoring get svc grafana-npNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana-np NodePort 10.111.59.2 <none> 80:30368/TCP,3000:31399/TCP 3h8m
Type in your browser : yourPublicDNS:yourPort and tada!
Grafana has user management capabilities, and by default, you must connect using the admin user.
To get the admin password, type the following :
kubectl get secret — namespace monitoring grafana -o jsonpath=”{.data.admin-password}” | base64 — decode ; echoADMINPASSWORD
Now you can connect.
The first step is to configure Prometheus as Data Source by using the internal DNS structure of Kubernetes:
http://prometheusServiceName.namespace.svc.cluster.local:port
Which is in my case :
http://prometheus-server.monitoring.svc.cluster.local (:80 optional)
Now that the datasource added, we will import two community dashboards useful for monitoring both our workload and the cluster health. They should work out of the box.
Click the import button and type Grafana dashboard ID:
Let’s install 1860 then 8685 which are complementary:
Now you should have two working dashboards:
We are now able to easily monitor both system metrics and cluster configuration!
Alerting on Slack Channel
Now that we have a working monitoring solution, the second step is to activate Alerting. We easily understand that an Ops team supervising several clusters in production cannot keep constantly an eye on their dashboards.
There are two ways to implement Alerting in our monitoring stack. We might use the prometheus AlertManager component (which is installed by the helm chart) or the built-in alerting function of Grafana. We’ll go for the latter as it’s easier to implement.
Grafana can send an alert on Slack, mail, webhook or other communication channels. As I’m using Slack a lot, and I know several companies do as well, I’ll go for this example.
Create the Slack notification channel
The first step is to add Slack as a notification channel. In grafana, click on the bell to the left, select the notification channel menu then create a new channel.
You’ll see the great number of tools compatible with Grafana for alerting.
Select Slack and enter the URL of your slack webhook URL (other fields are optional).
If you don’t have a webhook URL already follow this tutorial : https://api.slack.com/messaging/webhooks
It will help you create an endpoint for sending messages to a specific channel of your Slack server.
Create and test your custom alert
Now that your channel is set up, take your “K8S Cluster Summary” dashboard, and click on the Cluster Pod Capacity title, to edit the panel.
We will set up an alert to monitor the pod capacity, which is limited at 110 by Kubernetes by default on each node. This limit is considered as the limit of reliability. If the number of nodes in your cluster is limited and if you reach this hard limit of 110, the remaining pods will enter in a pending state which could be very problematic in a production cluster when scaling during a high business activity for example.
We’ll set up an alarm at 90 pods:
Back on our cluster let’s create an arbitrary deployment with 100 nginx replicas:
$ kubectl create ns loadtest
namespace loadtest created$ kubectl create deployment nginx --image=nginx -n loadtest
deployment.apps/nginx created$ kubectl -n loadtest scale deployment nginx --replicas=100
deployment.apps/nginx scaled
We can see the Pod capacity quickly rises to 115 because of the existing 15 initial pods in the cluster:
That’s 5 pods more than the allowed 110 and effectively we can see on the dashboards 5 pods are on pending state.
After 5 minutes the alert goes into ALERTING state and sends our notification on the Slack channel with the custom message and the current value .
We can scale down the deployment to 1 pod :
$ kubectl -n loadtest scale deployment nginx — replicas=1
deployment.apps/nginx scaledThe Pod Capacity has cooled down
And the alert sends a return to normal state notification to slack.
This little exercise was very interesting as it is fairly straightforward to implement but still gives a real world scenario.
There is something to note concerning the Grafana alerting feature. Both our dashboards are using functions called template variables. Variables are the values you can change on top of the dashboards like the host, cluster or namespace. By design, Grafana does not allow alerts on template variables for several reasons you can read here. If you try to put some alerts on certain panels on dashboards you may have an error for this reason. The solution will be to specify for each alert a specific host, cluster or node to monitor without using a variable.
Conclusion
After playing with Prometheus and Grafana, I hope you enjoyed this article and understood why monitoring is vital in the Kubernetes ecosystem.
